
- Published on
Leetcode 206 - Reverse Linked List
Hello and welcome to another algorithm problem review! Today we will continue diving down the linked list rabbit hole to discuss Leetcode 206 - Reverse Linked List
Problem statement and anaylsis
Our problem statement is quite simple for today:
Given the head of a singly linked list, reverse the list, and return the reversed list.
Sounds simple enough right? I am sure as a developer you have reversed one a many string or array in either your daily work or when completing algorithms. And it is easy to do so once you figure out that one little trick behind solving this specific problem. But today's solution is a bit unique (well maybe not that unique as we eventually move into trees) in that we are going to provide both the iterate and recursive solution to the problem.
But before we get started I want to clarify that we define a reverse linked list as one that the tail node becomes the head, the head node the tail, and all node reverse their next pointers to instead point at the preceeding node. Please also note that the linked list must not contain a cycle. If you need to know how to check whether a linked list has a cycle, I might suggest reading my blogpost discussing the cycle detection algorithm.
With that out of the way let's get started with the iterative approach!
Method 1 - Iterative solution
To be honest this solution is most likely what I believe a developer would intuitively come up with first. It shares a lot of similarities to other linked list solutions involving the use of constant memory space pointers. Let's begin with some psuedocode for the algorithm then talk through things
//first check to see if the list is empty or length one. If it is simply return the head argument
//initialize a previous pointer to null and current pointer to the head arg (classic 2 pointer helper approach)
//Loop while current is not null
// Initialize a temporary pointer called next and set it to the node after the current pointer
// set current pointer's next to be previous pointer's node
// now we are done, shift prev and current pointer "down" the list by one node
// return prev which is at the former tail node (but is actually the head now!)
A little confusing? That's okay! Let's step through this line by line.
The first line should be somewhat straightforward. If the linked list is empty or is of length 1 then there's no point in doing anything but the list is the same backwards and forwards. We can simply return the head arg as is. The second portion of looping through the entire linked list makes sense as we need to visit every node once in order to reverse the list.
Now using a third pointer in the loop may not make sense initially. If we already have a pointer pointing to previous and current, can't we derive the next pointer value? The answer is no due to the nature of linked lists. Let's review a diagram:
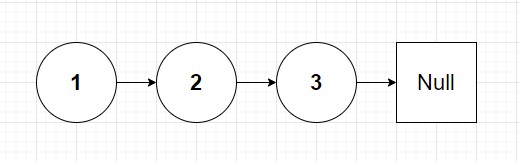
Here is a simple linked list consisting of 3 nodes 1, 2 and 3. We want to reverse this list such that when read from head to tail the nodes read back are 3, 2 and 1. Now let's apply our 2 pointer approach to the nodes for the first iteration:
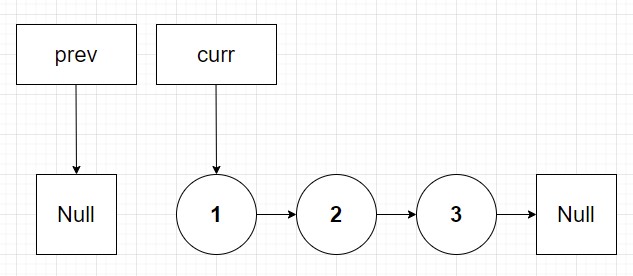
So as per our psuedocode our prev pointer will be set to null (it's outside the linked list initially) and curr will be set to the head node (node 1 in this case). We know we want node 1 to point to prev (null because this is the new tail of the linked list since we are reversing it). So as per the algorithm we set node 1's next pointer to prev (null):
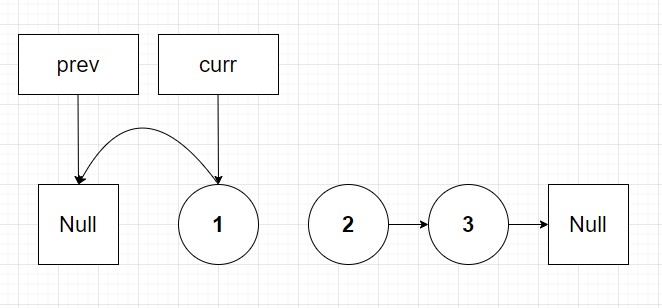
So far so good right? Now node 1 is pointing to null. We then proceed to set the curr pointer to the next pointer. But wait, we can't! As per the diagram above there's no arrow pointing to node 2. Recall, we set curr's next pointer to the prev pointer as the first step in our loop. Therefore the list is now completely separated from the rest of the list with no way to loop to subsequent nodes. As such the algorithm terminates because current is now null on next iteration.
Now that of course is not what we want. And thus the next pointer comes into play. Now let's add in that next pointer (on node 2):
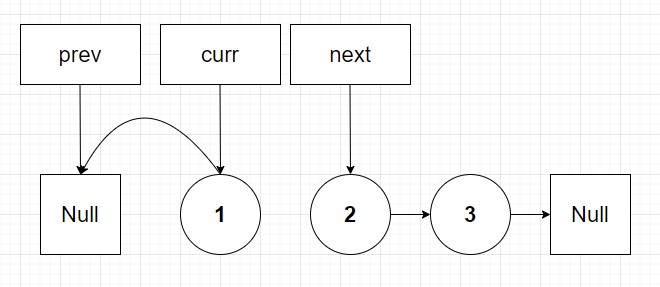
Ah that's much better! Even though we disconnected the first part of the linked list from the second part we now have a reference to the disconnected portion of the list. The break in the list is fine because we are going to reconnect this next node back to the other part of linked list in next iteration. So we finish by shifting our prev and current pointers by one:
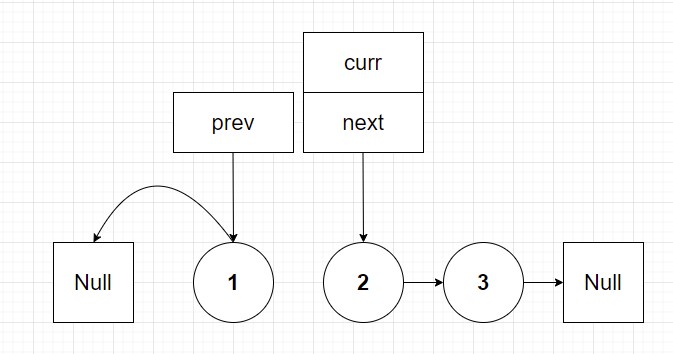
The pattern will continue for the second loop. I will quickly visually step through the second iteration of the linked list reverse:
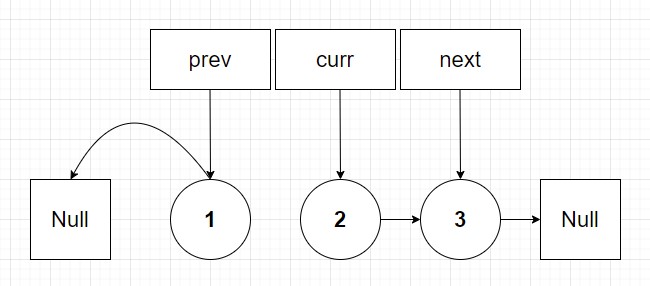
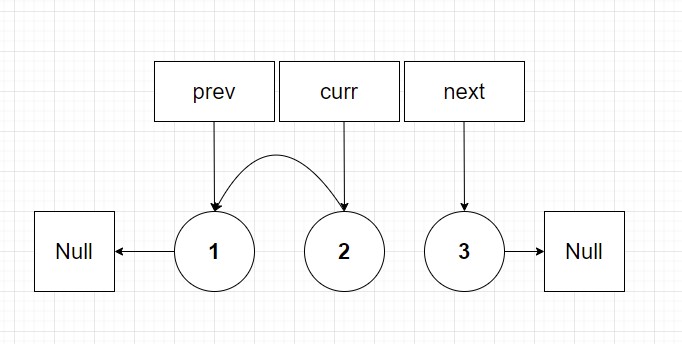
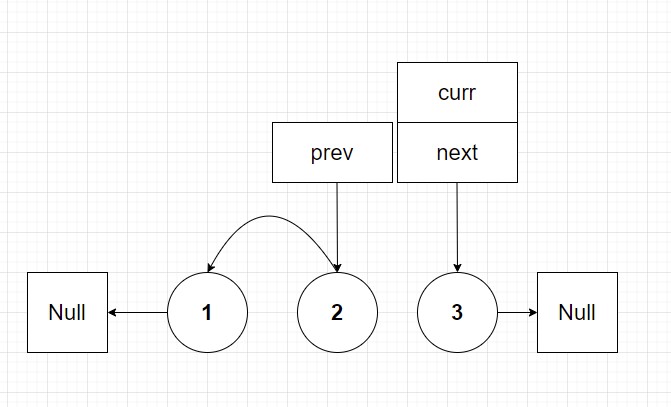
Now I invite the reader to do the final iteration on your own by drawing. I find personally start with pen and paper (or a tablet and pen) before coding is a great start to algorithms because it allows you to intuitively understand what is trying to be done before even writing a line of code. Then once you have a diagram that you can understand develop a psuedocode solution. Finally once armed with psuedocode should you start your language specific solution. Anyways the final list should look at follows:
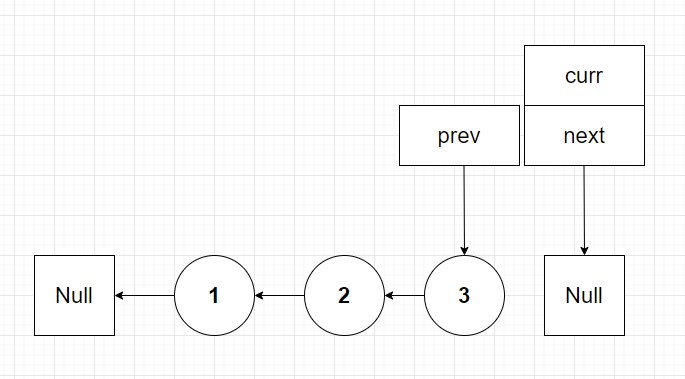
So from this diagram I hope it is more obvious why we return prev instead of the original head arg. Prev has now become our head node after reversal. Okay now that we have had fun drawing diagrams let's look at the code solution:
/**
* Definition for singly-linked list.
* class ListNode {
* val: number
* next: ListNode | null
* constructor(val?: number, next?: ListNode | null) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
* }
*/
function reverseList(head: ListNode | null): ListNode | null {
if (!head || head.next === null) return head;
let prev = null,
current = head;
while (current !== null) {
let next = current.next;
current.next = prev;
prev = current;
current = next;
}
//prev is new head now!
return prev;
}
Complexity analysis
Complexity analysis is actually quite similar to other two pointer approaches for singly linked lists. In order to reverse the list we must visit each node once. As such we have O(n) time complexity. In terms of space we just use 3 pointers. This does not scale larger with the linked list as such added space complexity is O(1).
Alright hopefully you have a better understanding of the iterative solution now. If not that's okay! Draw out some linked lists for yourself and draw the pointers progressing with each iteration. It will become clear eventually. Once you're ready lets proceed to the recursive solution.
Method 2 - Recursive solution
I'll be honest. Recursion is still something I am trying to improve as a concept I am quite good at. Quite often in day to day code I find myself reaching for iterative solutions. But actually reversing a linked list is a perfect example of where recursion can be quite eloquent. If you've never heard of recursion before it's simply a methodology where we more or less make nested calls with the same method in order to break up a larger problem into a set of sub problems we can solve.
So based on this information how can recursion help us? Well if you recall from the iterative solution at the end of each loop we basically had the exact same state just shifted by 1 node in the list. The actions we did every time were the exact same. But let's step back from the problem a bit further. What are we actually doing each iteration? Well if you invert your thinking a little bit what we are doing is taking an already inverted linked list and appending a node from the original linked list at the head of the new linked list. In other words we just keep working whats left of the original list each iteration until we have worked our way all the way through it. Now the recursive method does this the opposite way, but the concept of breaking the list into a smaller set of subproblems holds true as you will see in a bit.
So for our recursive method we essentially want to move to the end of our linked lists calling our reverseList() method each time we do so. And as part of each method call we add to our call stack we want to reverse the list one node at a time from back to front. Confusing? Let's start with some psuedocode.
//first check to see if the list is empty or length one. If it is simply return the head argument
//initialize a pointer and set its value equal to a recursive call to reverseList where the argument passed is the next node with respect to the node passed in to the upper function call.
//set the head argument's next next pointer to itself
//set the head argument's next pointer to null
//now return the pointer.
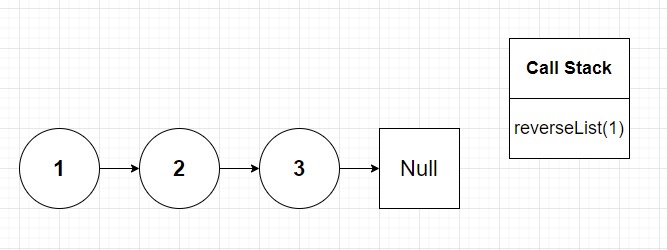
I bet you're still confused. That's okay! Let's now dive into diagram land once more. Starting out let's look at our original linked list:
Now what happens during first call of our reverseList() method? Well nothing exciting to be honest. We initialize our pointer to reverseList(head.next) which is added to our call stack:
Now let's fast forward two more steps and glance at the call stack:
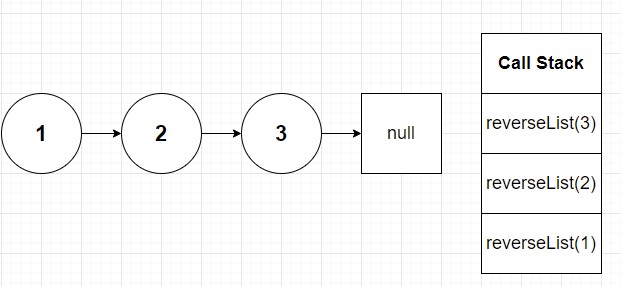
Now at this point we can probably guess head.next is easily pointing to null (3 points to null in our original linked list). At this point our first condition triggers in which head or head.next argument is null. So node 3 is returned and reverseList(node 3) is popped off the call stack. Now we follow the rest of the psuedocode algorithm.
This first step is actually the trickiest of all in my mind. We want the head arg node's next next pointer to point back to itself. But what does that actually mean? Now be very careful here you do not mix up ptr and head here. they are not the same thing.
At this point ptr and head correspond to nodes 1 and 2 respectively. As a reminder at point the order of the pointers in the list have also not changed. So lets break up the double call here. Head.next is actually node 3. This is again because node 2 points to node 3. Then we want node 3's next to point back to node 2, which is what our head argument holds. So it then looks something like this:
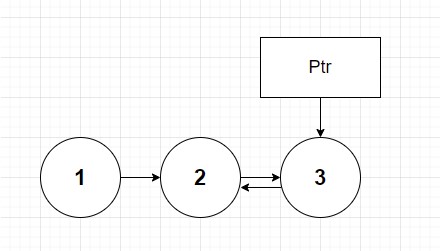
At this point you may think to yourself "uh oh". I must have made a mistake! But in actuality you are doing things exactly right. The last step of method asks us to set head.next to null. Or in this case we eliminate the arrow pointing between nodes 2 and 3:
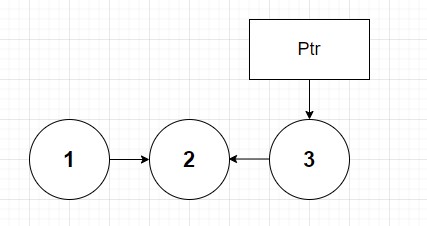
With this we pop reverseList(node 2) off the stack because we then return ptr (or node 1). Now we simply just have to complete the reverseList(node 1) call remaining on the stack. Let's now step through the algorithm line by line:
Step 1: Nodes 1 and 2 now point to each other since we set node 1's next.next to itself
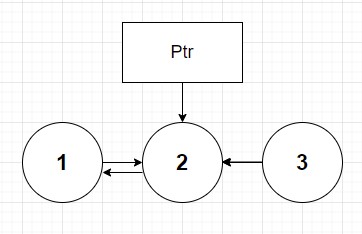
Step 2: We delete the pointer from node 1 to node 2 by setting it to null. This makes node 1 the new tail node
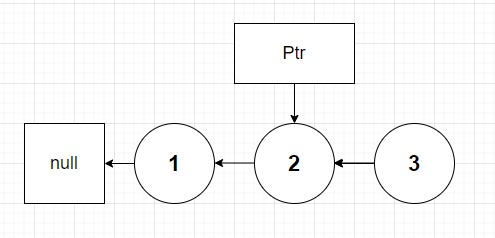
And at this point we are done because at the very top of our stack we returned 3 which now points to nodes 2 and 1 respectfully before terminating with null. Congratulations! 🥳 Now let's see the javascript implementation:
/**
* Definition for singly-linked list.
* class ListNode {
* val: number
* next: ListNode | null
* constructor(val?: number, next?: ListNode | null) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
* }
*/
function reverseList(head: ListNode | null): ListNode | null {
if (!head || head.next === null) return head;
const ptr = reverseList(head.next);
head.next.next = head;
head.next = null;
return ptr;
}
Complexity analysis
Well it was quite the journey to get to this point wouldn't you say? I think it should hopefully be intuitive that computational complexity remains O(n). It doesn't really matter whether we do this problem recursively or iteratively. We still need to at minimum check every node. Now space complexity becomes more interesting. In the iterative approach we had 3 pointer that did not scale with the length of the linked list. However that is not really true in the case of the resursive solution. Recall that we had a stack of function calls to work through. You already are reading my mind at this point. That stack height most certainly scales with the list length. As such for the recursive reverse list solution our space completely unfortunately comes out to O(n).
This is probably my longest blog post to date. Thank you so much for lasting this long and I hope this helps you demystify reversing linked lists.